|
I'm a PhD student at the University of Amsterdam, working with Marcel Worring and Yuki Asano. I work on multimodal foundation models at the Informatics Institute, where I'm part of MultiX Amsterdam and AIMLab groups. I am a member of the ELLIS Society and have served as a reviewer for leading conferences, including CVPR, ICCV, NeurIPS, ICLR, and ICML.
In 2023 I spent time as a Research Scientist Intern in Meta GenAI, working on image generation and in-context learning. I obtained my master degree in Artificial Inteligence at the KU Leuven. Before that, I spent some time as a Software Engineer in Netcetera and I was an undergraduate student in Computer Science and Engineering at the FCSE at University ”Ss. Cyril and Methodius” in Skopje. Email / Twitter / Google Scholar / Github / LinkedIn |

|
|
|
My research centers around multimodal foundation models - with focus on designing efficient approaches for multimodal understanding and generative tasks. I'm interested in better understanding what large-scale models learn, and how to exploit that through in-context learning and prompting. Some of my work also includes automated linguistic interpretation of images, as well as its applications in the medical domain. |
|
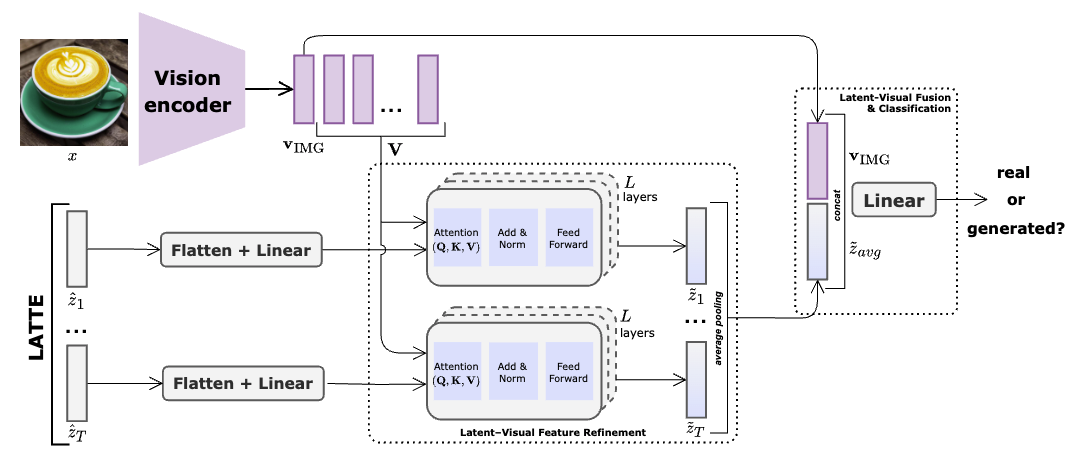
Ana Vasilcou*, Ivona Najdenkoska*, Zeno Geradts, Marcel Worring Preprint (arxiv 2025) paper | code We present LATTE - Latent Trajectory Embedding - a novel approach for AI-generated image detection, which models the evolution of latent embeddings across several denoising timesteps. |
|
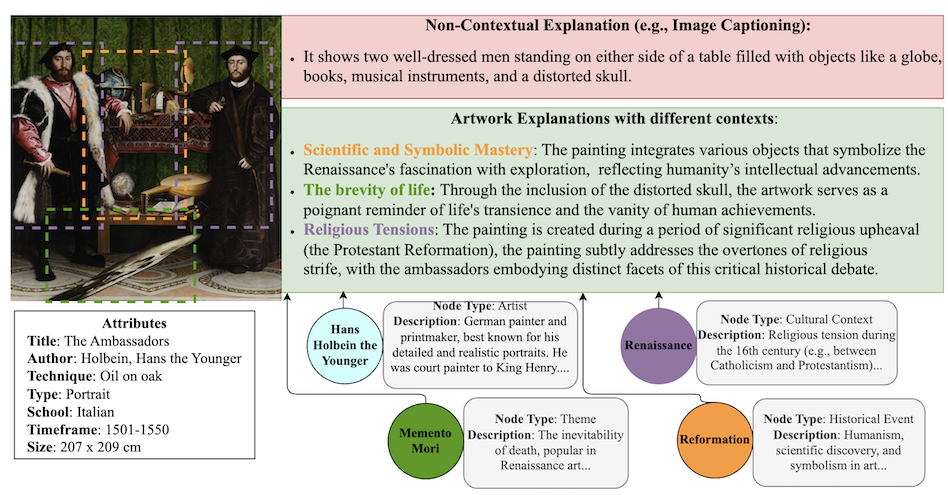
Shuai Wang, Ivona Najdenkoska, Hongyi Zhu Stevan Rudinac Monika Kackovic Nachoem Wijnberg Marcel Worring In ACMMM 2025 paper We present ArtRAG - novel training-free framework that integrates structured knowledge into a RAG pipeline for multi-perspective artwork explanation. |
|
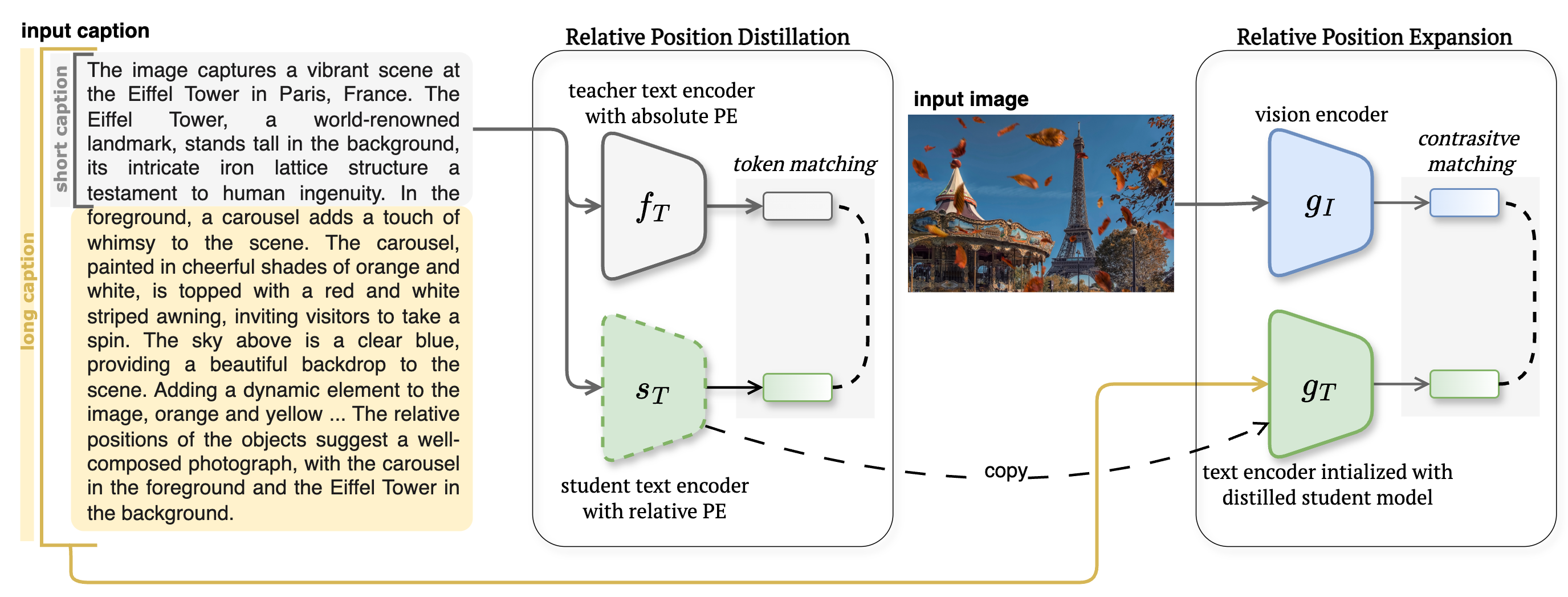
Ivona Najdenkoska*, Mohammad M. Derakshani*, Yuki M. Asano, Nanne van Noord, Marcel Worring, Cees Snoek In ICLR 2025 paper | code | Long-DCI benchmark We propose TULIP, a generalizable method able to upgrade the token length to any length for CLIP-like models. |

|
Ivona Najdenkoska, Animesh Sinha, Abhimanyu Dubey, Dhruv Mahajan, Vignesh Ramanathan, Filip Radenovic In ECCV 2024 paper | project page We present Context Diffusion, an in-context-aware image generation framework capable of learning from a variable number of visual context examples and prompts. |
|
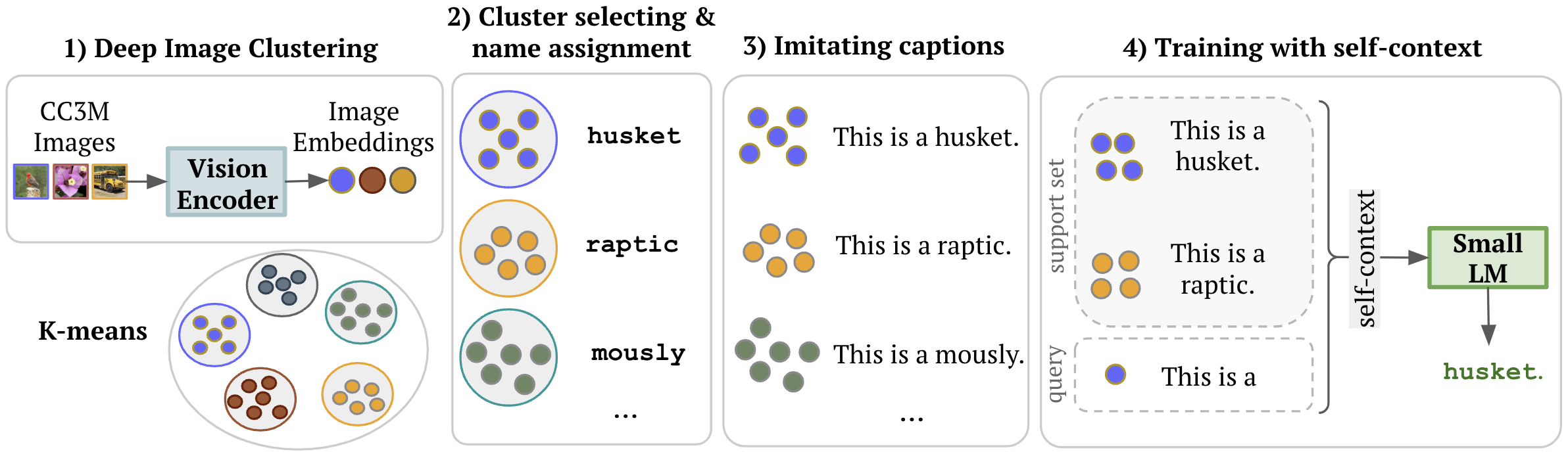
Mohammad M. Derakshani*, Ivona Najdenkoska*, Cees Snoek, Marcel Worring, Yuki M. Asano In ICLR ME-FoMo 2024 paper We present Self-Context Adaptation (SeCAt), a selfsupervised approach that unlocks few-shot open-ended classification with small visual language models. |
|
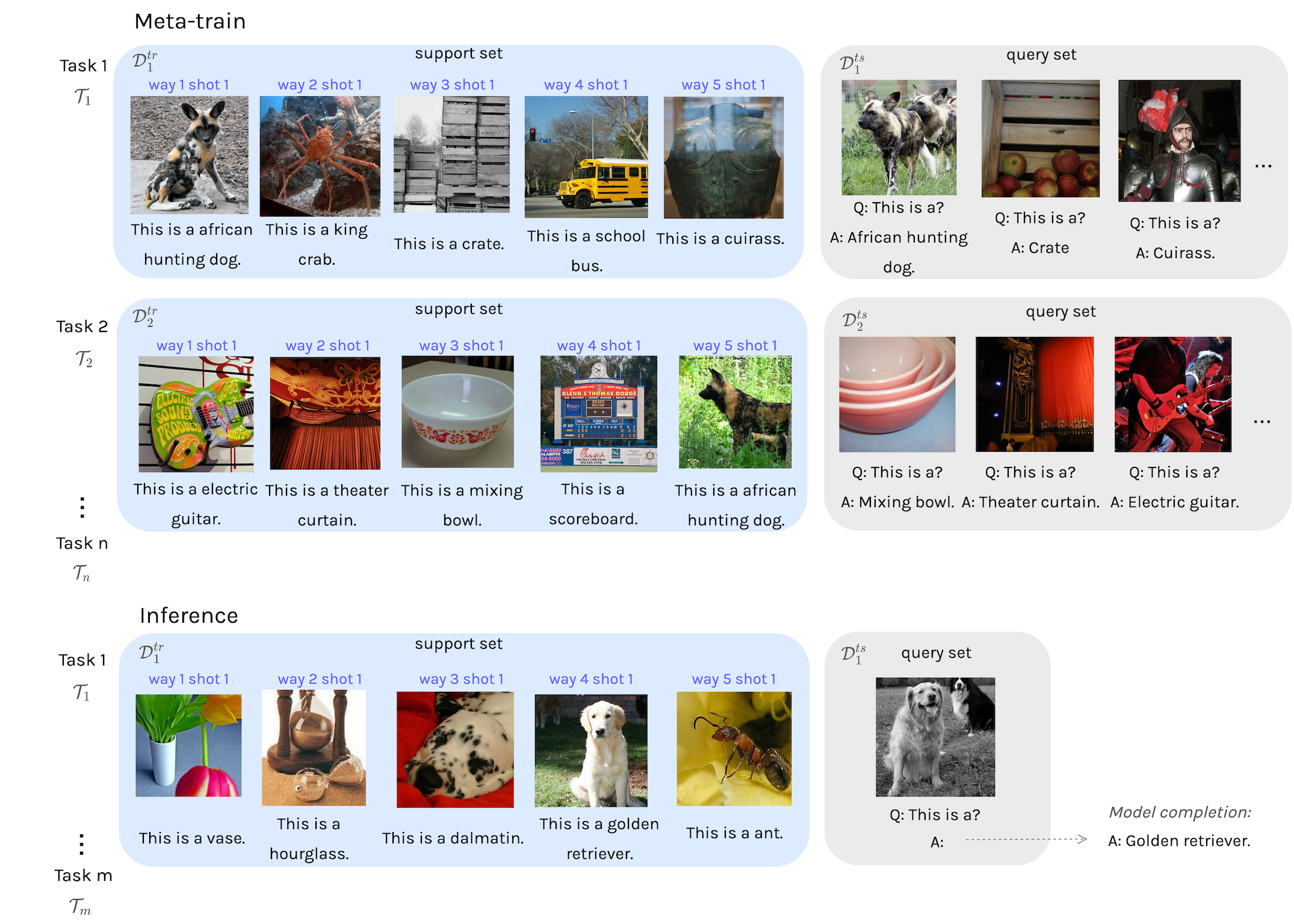
Ivona Najdenkoska, Xiantong Zhen, Marcel Worring In ICLR 2023 paper | code We propose a method for bridging large-scale vision and language models to perform multimodal few-shot learning. The model meta-learns visual prefixes from frozen visual backbone, which are used as prompts to a large langauge model. |
|
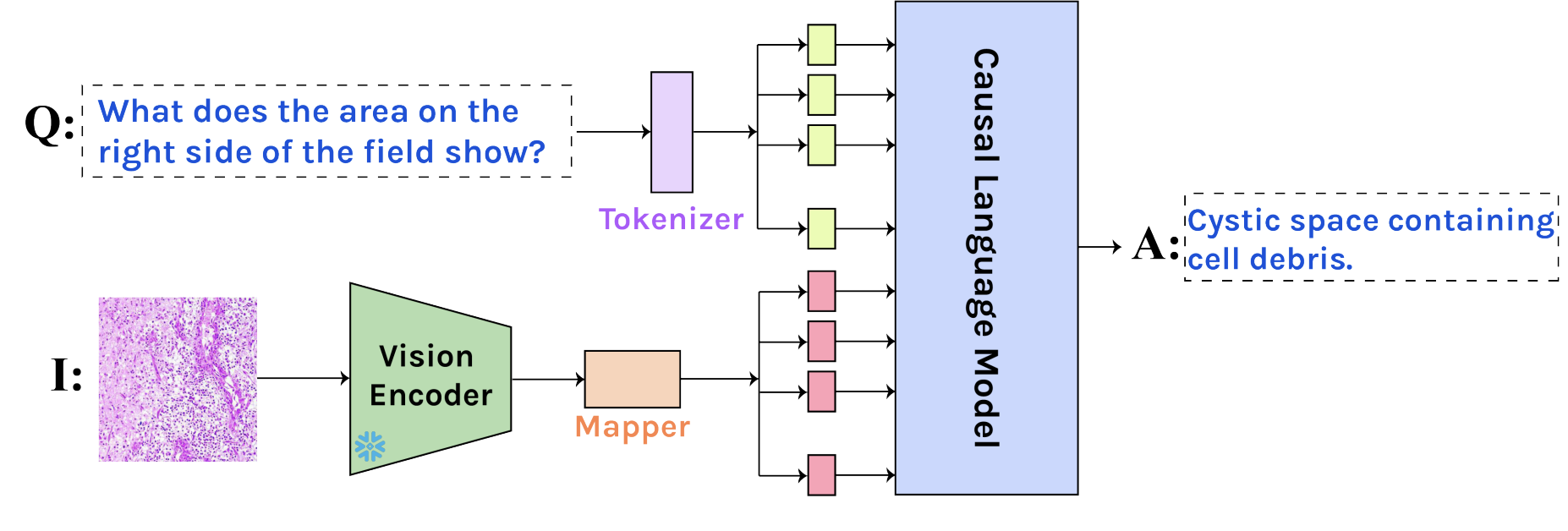
Tom van Sonsbeek*, Mohammad M. Derakshani*, Ivona Najdenkoska*, Cees Snoek, Marcel Worring In MICCAI 2023, Oral paper | code We introduce a novel method for open-ended VQA suited for small, domain-specific, medical datasets. We employ parameter-efficient strategies for efficient tuning of the LMs. |
|
Ivona Najdenkoska, Xiantong Zhen, Marcel Worring In 6th Workshop on Meta-Learning at NeurIPS 2022 paper We define a meta-learning approach for multimodal few-shot learning, to leverage its strong ability of accruing knowledge across tasks (predecessor of the ICLR 2023 work). |
|
Ivona Najdenkoska, Xiantong Zhen, Marcel Worring, Ling Shao In Medical Image Analysis 2022, Best Paper Honorable Mention paper | code We present a probabilistic latent variable model for chest X-Ray report generation. We extend the VTI model by providing a fully Transformer-based definition and explore the trade-off between an LSTM- or Transformer-based decoder for generation of medical text. |
|
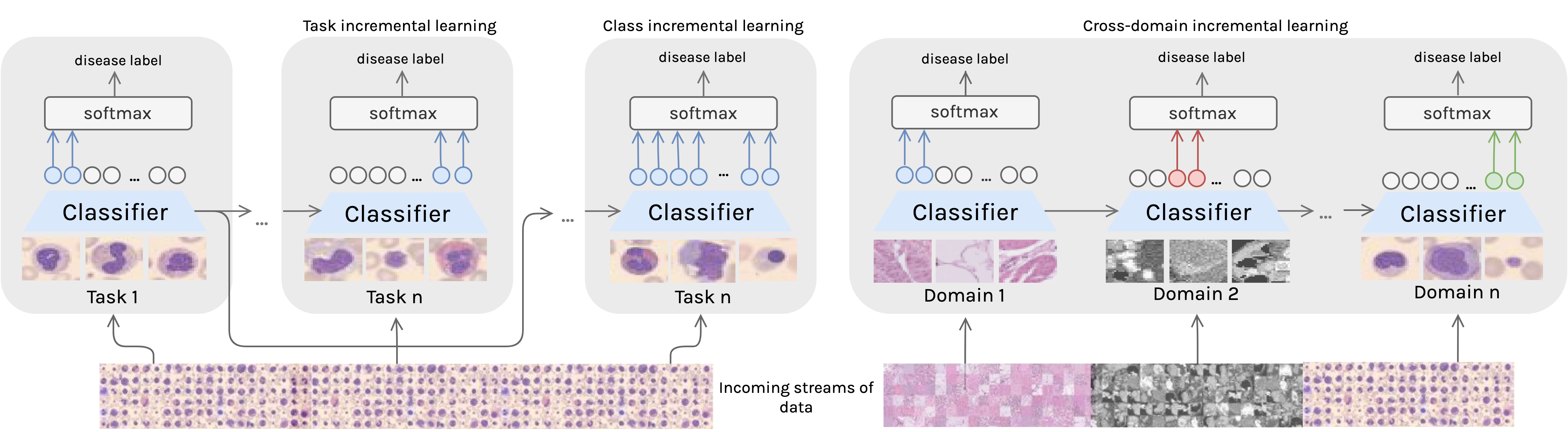
Mohammad M. Derakshani*, Ivona Najdenkoska*, Tom van Sonsbeek*, Xiantong Zhen, Dwarikanath Mahapatra, Marcel Worring, Cees Snoek In MICCAI 2022 paper | code | project page We introduce LifeLonger, a benchmark for continual disease classification on the MedMNIST collection, by applying existing state-of-the-art continual learning methods. |
|
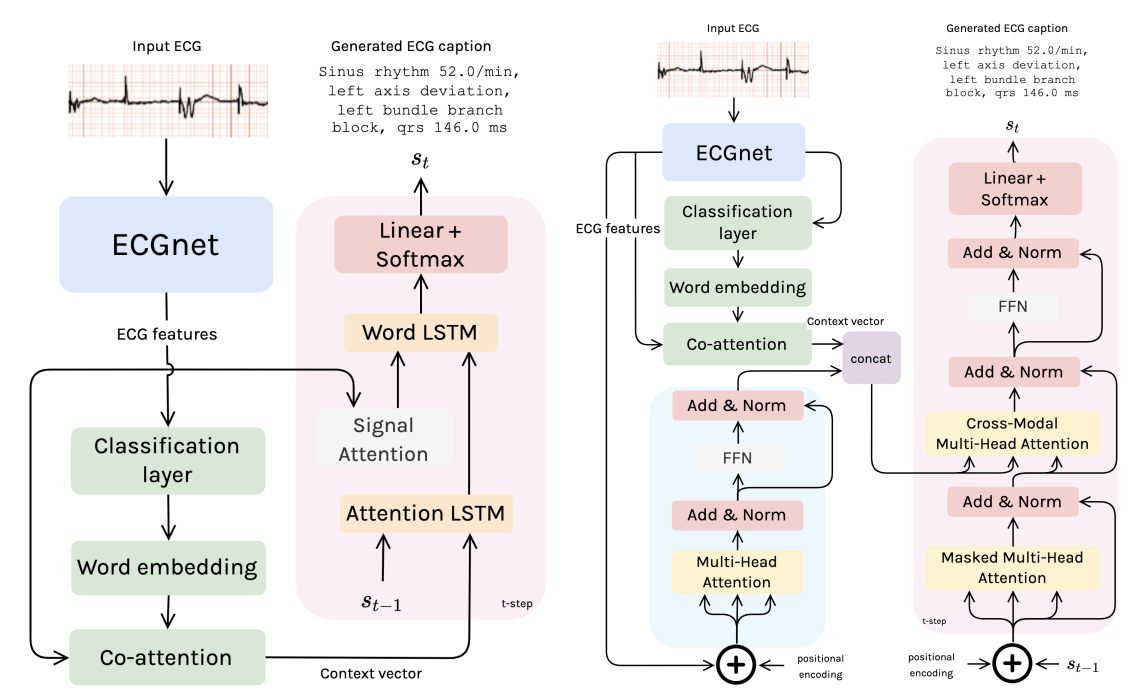
Mathieu G. G. Bartels, Ivona Najdenkoska, Rutger van de Leur, Arjan Sammani, Karim Taha, David M. Knigge, Pieter Doevendans, Marcel Worring, Rene van Es In MIDL 2022 paper We introduce a label-guided Transformer model, and show that it is possible to automatically generate relevant and readable ECG descriptions with a data-driven captioning model. |
|
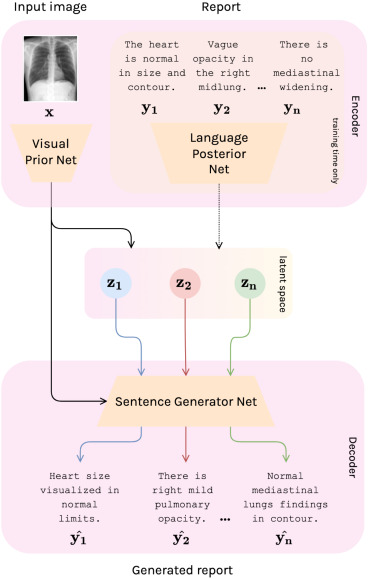
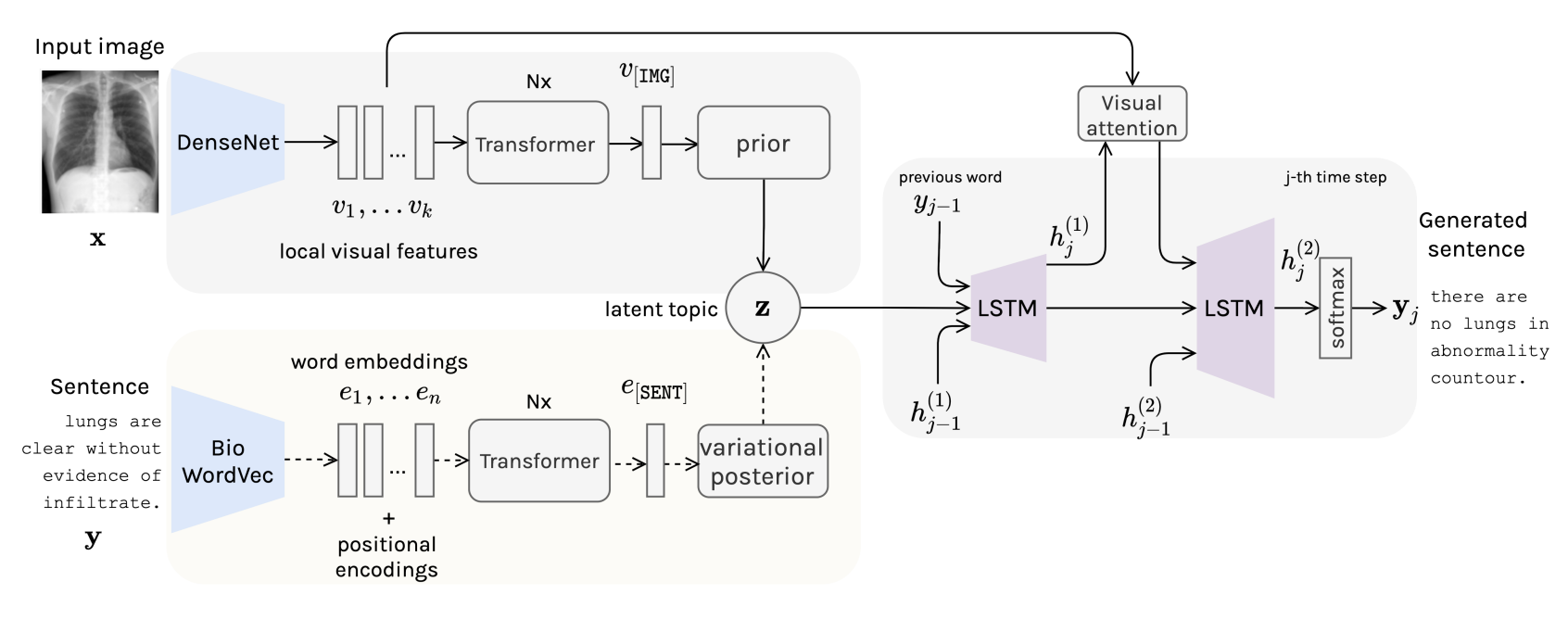
Ivona Najdenkoska, Xiantong Zhen, Marcel Worring, Ling Shao In MICCAI 2021, Oral + Travel Award paper | code We propose Variational Topic Inference (VTI), a probabilistic latent variable model for automatic report generation. We introduce a set of topics as latent variables to guide sentence generation by aligning image and language modalities in the latent space. |
|
|
|
|
|
|
|
|